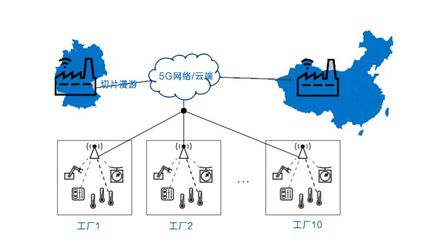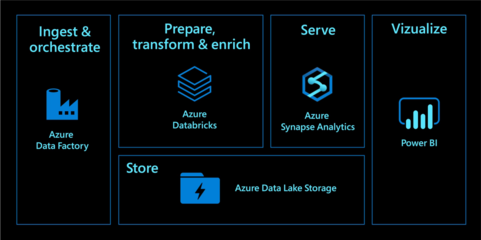
Hadoop 是當(dāng)今大數(shù)據(jù)領(lǐng)域的核心技術(shù)之一,以其高效的數(shù)據(jù)處理與存儲能力廣泛應(yīng)用于各行各業(yè)。作為大數(shù)據(jù)生態(tài)系統(tǒng)的重要支柱,Hadoop 提供了一套可靠的分布式數(shù)據(jù)存儲和處理框架,能夠處理海量結(jié)構(gòu)化與非結(jié)構(gòu)化數(shù)據(jù)。本部分將重點介紹 Hadoop 的架構(gòu)組成,以及大數(shù)據(jù)存儲與數(shù)據(jù)處理服務(wù)的基本原理和實現(xiàn)方式。
一、Hadoop 架構(gòu)概述
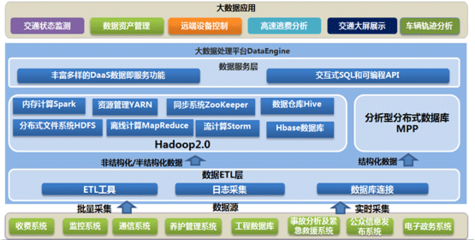
Hadoop 架構(gòu)主要由兩大核心組件構(gòu)成:HDFS(Hadoop 分布式文件系統(tǒng))和 MapReduce。HDFS 負(fù)責(zé)數(shù)據(jù)的分布式存儲,它將大規(guī)模數(shù)據(jù)分割成塊(blocks),并分散存儲于集群中的多個節(jié)點,確保數(shù)據(jù)的高可用性和容錯性。而 MapReduce 則是一種分布式計算模型,包含兩個階段:Map 階段負(fù)責(zé)數(shù)據(jù)的并行處理與轉(zhuǎn)換,Reduce 階段則對中間結(jié)果進行匯總,生成最終輸出。Hadoop 還包括 YARN(Yet Another Resource Negotiator)作為資源管理器,用于分配計算資源和管理任務(wù)調(diào)度,進一步優(yōu)化了集群性能。
二、大數(shù)據(jù)存儲服務(wù)
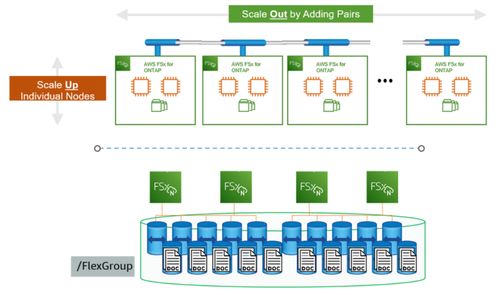
Hadoop 的核心存儲服務(wù)依賴于 HDFS。HDFS 設(shè)計初衷是支持海量數(shù)據(jù)存儲,適合一次寫入、多次讀取的場景。它采用主從架構(gòu),包括 NameNode(主節(jié)點)和多個 DataNode(從節(jié)點)。NameNode 負(fù)責(zé)管理文件系統(tǒng)的元數(shù)據(jù)(如文件和目錄結(jié)構(gòu)),而 DataNode 則存儲實際數(shù)據(jù)塊。這種分布式存儲方式不僅提升了數(shù)據(jù)的可靠性和冗余備份能力,還能通過橫向擴展輕松應(yīng)對數(shù)據(jù)增長。除了 HDFS,Hadoop 生態(tài)中還有其他存儲選項,例如 HBase(分布式 NoSQL 數(shù)據(jù)庫),適用于實時讀寫場景,以及云存儲服務(wù)整合,為大數(shù)據(jù)應(yīng)用提供靈活性和擴展性。
三、數(shù)據(jù)處理與存儲服務(wù)集成
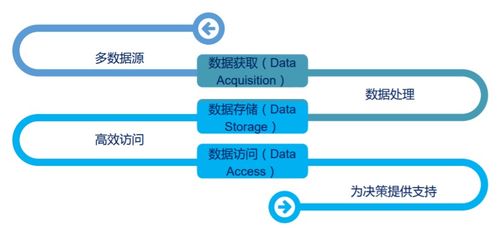
在 Hadoop 框架下,數(shù)據(jù)處理與存儲服務(wù)緊密結(jié)合,共同支持大數(shù)據(jù)應(yīng)用。MapReduce 作為經(jīng)典的數(shù)據(jù)處理引擎,可以高效處理存儲在 HDFS 上的數(shù)據(jù),實現(xiàn)批量計算任務(wù)。隨著技術(shù)演進,Hadoop 生態(tài)系統(tǒng)還引入了更高級的處理工具,如 Apache Spark,它通過內(nèi)存計算加速數(shù)據(jù)處理過程,并支持流處理和機器學(xué)習(xí)。數(shù)據(jù)倉庫解決方案如 Hive 和 Pig 提供了類 SQL 接口,簡化了數(shù)據(jù)查詢與分析。這些服務(wù)通過集成的資源管理(如 YARN)和存儲抽象,使企業(yè)能夠構(gòu)建可擴展的大數(shù)據(jù)平臺,有效應(yīng)對數(shù)據(jù)存儲、處理和分析的多樣化需求。
Hadoop 架構(gòu)通過其分布式文件系統(tǒng)和并行計算能力,奠定了大數(shù)據(jù)存儲與處理的基礎(chǔ)。理解 HDFS 的存儲機制和 MapReduce 的數(shù)據(jù)處理流程,是掌握大數(shù)據(jù)技術(shù)的關(guān)鍵。隨著云計算和實時分析需求的增長,Hadoop 生態(tài)持續(xù)演進,提供更加高效、靈活的數(shù)據(jù)服務(wù),助力企業(yè)從海量數(shù)據(jù)中提取價值。