JBD2與Hadoop:高效數(shù)據(jù)處理與存儲(chǔ)服務(wù)的融合
引言
在大數(shù)據(jù)時(shí)代,數(shù)據(jù)處理與存儲(chǔ)的效率直接決定了企業(yè)數(shù)據(jù)應(yīng)用的能力。Linux內(nèi)核中的JBD2(Journaling Block Device 2)與分布式計(jì)算框架Hadoop的結(jié)合,為海量數(shù)據(jù)的可靠存儲(chǔ)與高效處理提供了堅(jiān)實(shí)的技術(shù)基礎(chǔ)。本文將探討JBD2如何為Hadoop的數(shù)據(jù)存儲(chǔ)提供底層支持,以及兩者結(jié)合帶來的優(yōu)勢與挑戰(zhàn)。
一、JBD2:可靠的存儲(chǔ)基石
JBD2是Linux內(nèi)核中為文件系統(tǒng)提供日志(Journaling)功能的核心模塊,主要用于ext4文件系統(tǒng)。其核心價(jià)值在于:
- 數(shù)據(jù)一致性保障:通過寫前日志(Write-Ahead Logging)機(jī)制,確保即使在系統(tǒng)崩潰或意外斷電時(shí),文件系統(tǒng)也能快速恢復(fù)至一致狀態(tài),避免數(shù)據(jù)損壞。
- 高性能寫入:將隨機(jī)寫入轉(zhuǎn)化為順序?qū)懭耄@著提升磁盤I/O效率,尤其適用于Hadoop中頻繁的數(shù)據(jù)寫入場景。
- 元數(shù)據(jù)保護(hù):優(yōu)先保護(hù)文件系統(tǒng)元數(shù)據(jù),這是保證Hadoop分布式文件系統(tǒng)(如HDFS)目錄結(jié)構(gòu)完整性的關(guān)鍵。
在Hadoop集群中,每個(gè)數(shù)據(jù)節(jié)點(diǎn)(DataNode)通常使用ext4文件系統(tǒng)來存儲(chǔ)HDFS數(shù)據(jù)塊,JBD2的日志功能為這些數(shù)據(jù)塊的元數(shù)據(jù)操作提供了原子性和持久性保證,是HDFS高可靠性的重要底層支撐。
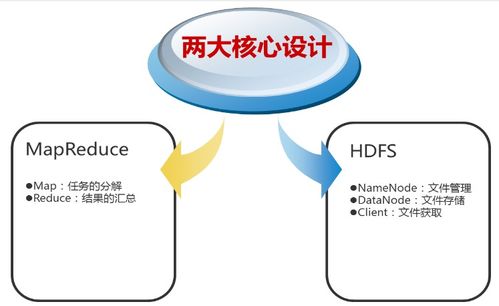
二、Hadoop:分布式處理與存儲(chǔ)的引擎
Hadoop是一個(gè)開源的分布式系統(tǒng)基礎(chǔ)架構(gòu),其核心組件包括:
- HDFS(Hadoop Distributed File System):高容錯(cuò)性的分布式文件系統(tǒng),設(shè)計(jì)用于在廉價(jià)硬件上存儲(chǔ)超大規(guī)模數(shù)據(jù)集。
- MapReduce:分布式計(jì)算框架,用于并行處理海量數(shù)據(jù)。
- YARN:資源管理與作業(yè)調(diào)度框架。
HDFS將大文件分割成多個(gè)數(shù)據(jù)塊(默認(rèn)為128MB或256MB),并跨集群中的多個(gè)數(shù)據(jù)節(jié)點(diǎn)進(jìn)行復(fù)制存儲(chǔ)(默認(rèn)為3副本),從而實(shí)現(xiàn)數(shù)據(jù)的可靠存儲(chǔ)與高吞吐量訪問。
三、JBD2與Hadoop的協(xié)同工作
在實(shí)際部署中,JBD2與Hadoop的協(xié)同主要體現(xiàn)在存儲(chǔ)層面:
- 數(shù)據(jù)寫入流程:
- 當(dāng)HDFS客戶端寫入數(shù)據(jù)時(shí),數(shù)據(jù)首先被分成塊,并并行寫入多個(gè)數(shù)據(jù)節(jié)點(diǎn)。
- 數(shù)據(jù)節(jié)點(diǎn)的本地文件系統(tǒng)(如ext4)接收到寫入請求后,JBD2會(huì)先將本次寫入的元數(shù)據(jù)變更記錄到日志中,再實(shí)際修改文件系統(tǒng)。
- 這種機(jī)制確保了即使寫入過程中系統(tǒng)崩潰,恢復(fù)后也能根據(jù)日志重放或撤銷未完成的操作,保證HDFS數(shù)據(jù)塊元數(shù)據(jù)(如inode、塊映射)的一致性。
- 故障恢復(fù)加速:
- Hadoop集群規(guī)模龐大,節(jié)點(diǎn)故障是常態(tài)。當(dāng)某個(gè)數(shù)據(jù)節(jié)點(diǎn)重啟時(shí),ext4文件系統(tǒng)借助JBD2可以快速恢復(fù)一致性狀態(tài),無需漫長的fsck檢查,從而縮短節(jié)點(diǎn)恢復(fù)時(shí)間,提升集群整體可用性。
- 性能調(diào)優(yōu)考量:
- 日志模式選擇:ext4提供了
journal(全數(shù)據(jù)日志)、ordered(僅元數(shù)據(jù)日志,默認(rèn))和writeback三種日志模式。對于Hadoop,ordered模式在保證元數(shù)據(jù)一致性的性能開銷較小,通常是推薦設(shè)置。
- 日志設(shè)備分離:在高性能集群中,可以將JBD2日志存放在單獨(dú)的SSD或NVMe設(shè)備上,進(jìn)一步減少日志寫入對數(shù)據(jù)磁盤I/O的干擾,提升整體吞吐量。
四、優(yōu)勢與挑戰(zhàn)
優(yōu)勢:
- 增強(qiáng)的可靠性:JBD2為Hadoop底層存儲(chǔ)提供了企業(yè)級的數(shù)據(jù)一致性保障。
- 提升的寫入性能:日志機(jī)制將隨機(jī)寫轉(zhuǎn)為順序?qū)懀鹾洗疟P物理特性,有利于HDFS的大量數(shù)據(jù)寫入作業(yè)。
- 快速故障恢復(fù):減少因節(jié)點(diǎn)重啟導(dǎo)致的數(shù)據(jù)不可用時(shí)間,符合Hadoop設(shè)計(jì)的高容錯(cuò)目標(biāo)。
挑戰(zhàn)與注意事項(xiàng):
- 性能開銷:日志寫入帶來額外的I/O操作,在極端寫入負(fù)載下可能成為瓶頸。需根據(jù)工作負(fù)載特點(diǎn)調(diào)整日志參數(shù)(如提交間隔)。
- 配置復(fù)雜性:優(yōu)化JBD2與ext4參數(shù)(如
data=ordered,journal_dev)需要一定的系統(tǒng)管理經(jīng)驗(yàn)。 - 替代方案:對于追求極致性能的場景,部分企業(yè)會(huì)考慮使用XFS或ZFS等其他文件系統(tǒng),它們采用不同的日志或?qū)憰r(shí)復(fù)制(Copy-on-Write)機(jī)制,與Hadoop的適配性也需評估。
五、最佳實(shí)踐建議
- 文件系統(tǒng)配置:在Hadoop數(shù)據(jù)節(jié)點(diǎn)上格式化ext4時(shí),建議使用
mkfs.ext4 -O ^has_journal先禁用日志,然后用tune2fs -j添加日志,以便正確對齊日志參數(shù)。掛載時(shí)使用defaults,noatime,nodiratime,data=ordered選項(xiàng)。 - 監(jiān)控與調(diào)優(yōu):監(jiān)控JBD2的日志寫入量(可通過
iostat -x或/proc/fs/jbd2/查看)以及磁盤利用率,根據(jù)實(shí)際情況調(diào)整/proc/sys/fs/jbd2/下的內(nèi)核參數(shù)(如commit_timeout)。 - 硬件優(yōu)化:若條件允許,為日志分配獨(dú)立的閃存設(shè)備,并確保數(shù)據(jù)磁盤使用RAID或JBOD配置符合Hadoop的冗余設(shè)計(jì)理念。
結(jié)論
JBD2作為Linux內(nèi)核中成熟的日志塊設(shè)備層,為Hadoop的分布式存儲(chǔ)提供了不可或缺的底層數(shù)據(jù)一致性保障。雖然引入了一定的復(fù)雜度與性能考量,但其在可靠性與故障恢復(fù)方面的價(jià)值,使其成為生產(chǎn)環(huán)境Hadoop集群存儲(chǔ)基石的常見選擇。深入理解JBD2的工作原理,并結(jié)合Hadoop的數(shù)據(jù)訪問模式進(jìn)行針對性調(diào)優(yōu),能夠有效構(gòu)建出既穩(wěn)健又高效的大數(shù)據(jù)處理與存儲(chǔ)服務(wù)平臺(tái)。隨著存儲(chǔ)硬件與文件系統(tǒng)技術(shù)的不斷發(fā)展,這種協(xié)同也將持續(xù)演進(jìn),以應(yīng)對日益增長的數(shù)據(jù)挑戰(zhàn)。